2012年5月17日,Google正式提出了知识图谱(Knowledge Graph)的概念,其初衷是为了优化搜索引擎返回的结果,增强用户搜索质量及体验。
实际上,知识图谱并不是一个全新的概念,早在 2006 年就有文献提出了语义网(Semantic Network)的概念,呼吁推广、完善使用本体模型来形式化表达数据中的隐含语义,RDF(resource description framework,资源描述框架)模式和 OWL(Web ontology language,万维网本体语言)就是基于上述目的产生的。用电子科技大学徐增林教授的论文原文来说:
知识图谱技术的出现正是基于以上相关研究,是对语义网标准与技术的一次扬弃与升华。
目前,随着智能信息服务应用的不断发展,知识图谱已广泛应用于智能搜索,智能问答,个性化推荐等领域。
2. 定义
知识图谱,本质上,是一种揭示实体之间关系的语义网络。
看一张简单的知识图谱:
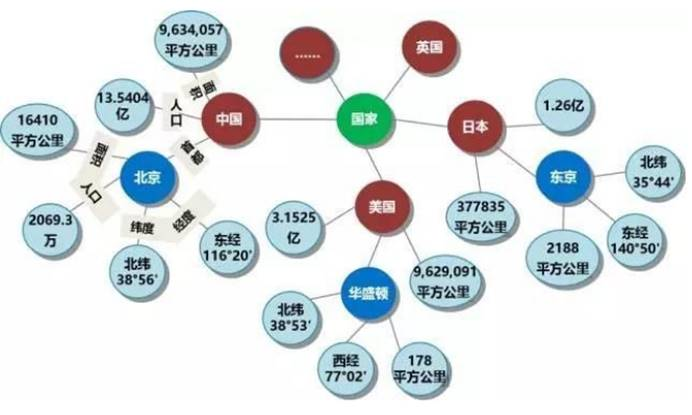
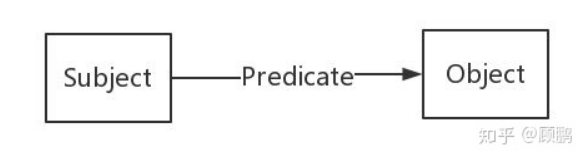
如图所示,你可以看到,如果两个节点之间存在关系,他们就会被一条无向边连接在一起,那么这个节点,我们就称为实体(Entity),它们之间的这条边,我们就称为关系(Relationship)。
如果你看过网络综艺《奇葩说》第五季第17期:你是否支持全人类一秒知识共享,你也许会被辩手陈铭的辩论印象深刻。他在节目中区分了信息和知识两个概念:
信息是指外部的客观事实。举例:这里有一瓶水,它现在是7°。
知识是对外部客观规律的归纳和总结。举例:水在零度的时候会结冰。
“客观规律的归纳和总结” 似乎有些难以实现。Quora 上有另一种经典的解读,区分 “信息” 和 “知识” 。
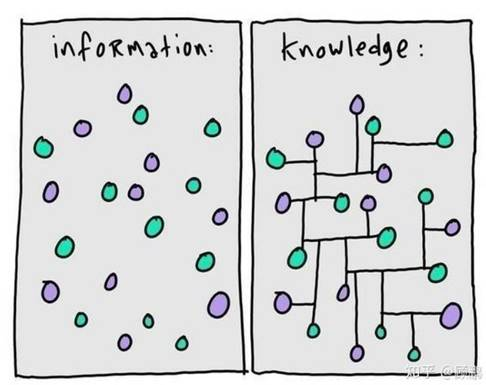
这样我们就很容易理解,在信息的基础上,建立实体之间的联系,就能行成 “知识”,或者称为叫事实(Fact)更为合适。换句话说,知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
知识图谱实际上就是如此工作的。曾经知识图谱非常流行自顶向下(top-down)的构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库,例如 Freebase 项目就是采用这种方式,它的绝大部分数据是从维基百科中得到的。
然而目前,大多数知识图谱都采用自底向上(bottom-up)的构建方式。自底向上指的是从一些开放链接数据(也就是 “信息”)中提取出实体,选择其中置信度较高的加入到知识库,再构建实体与实体之间的联系。
3. 数据类型和存储方式
知识图谱的原始数据类型一般来说有三类(也是互联网上的三类原始数据):
如何存储上面这三类数据类型呢?一般有两种选择,一个是通过RDF(资源描述框架)这样的规范存储格式来进行存储,还有一种方法,就是使用图数据库来进行存储,常用的有Neo4j等。
4. 体系架构
知识图谱的架构主要包括自身的逻辑结构以及体系架构。
知识图谱在逻辑结构上可分为模式层与数据层两个层次,数据层主要是由一系列的事实组成,而知识将以事实为单位进行存储。如果用(实体1,关系,实体2)、(实体、属性,属性值)这样的三元组来表达事实,可选择图数据库作为存储介质,例如开源的 Neo4j、Twitter 的 FlockDB、JanusGraph 等。模式层构建在数据层之上,主要是通过本体库来规范数据层的一系列事实表达。本体是结构化知识库的概念模板,通过本体库而形成的知识库不仅层次结构较强,并且冗余程度较小。
知识图谱的体系架构是指其构建模式的结构,如下图所示:
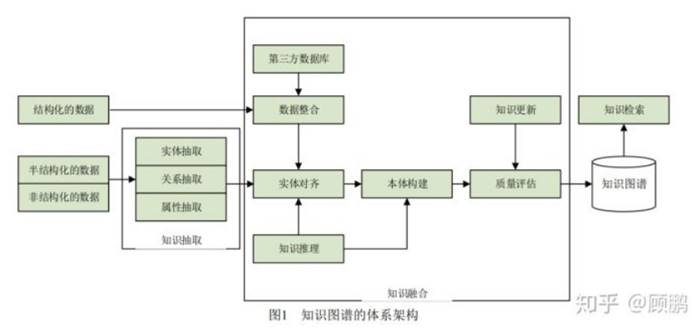
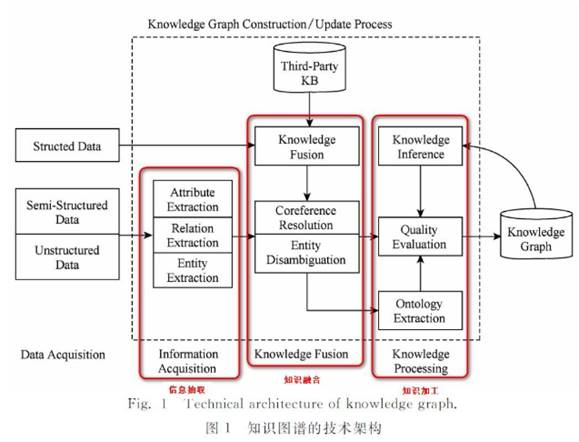
大规模知识库的构建与应用需要多种智能信息处理技术的支持。通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。
5. 知识抽取
知识抽取主要是面向开放的链接数据,通过自动化的技术抽取出可用的知识单元,知识单元主要包括实体(概念的外延)、关系以及属性3个知识要素,并以此为基础,形成一系列高质量的事实表达,为上层模式层的构建奠定基础。知识抽取有三个主要工作:
6. 知识表示
近年来,以深度学习为代表的表示学习技术取得了重要的进展,可以将实体的语义信息表示为稠密低维实值向量,进而在低维空间中高效计算实体、关系及其之间的复杂语义关联,对知识库的构建、推理、融合以及应用均具有重要的意义。
7. 知识融合
由于知识图谱中的知识来源广泛,存在知识质量良莠不齐、来自不同数据源的知识重复、知识间的关联不够明确等问题,所以必须要进行知识的融合。知识融合是高层次的知识组织,使来自不同知识源的知识在同一框架规范下进行异构数据整合、消歧、加工、推理验证、更新等步骤,达到数据、信息、方法、经验以及人的思想的融合,形成高质量的知识库。知识融合包括两部分内容:实体链接,知识合并。
8. 知识加工
事实本身并不等于知识。要想最终获得结构化,网络化的知识体系,还需要经历知识加工的过程。知识加工主要包括三方面内容:本体构建、知识推理和质量评估。
9. 知识更新
从逻辑上看,知识库的更新包括概念层的更新和数据层的更新。
知识图谱的内容更新有两种方式:
10. 知识图谱应用
知识图谱为互联网上海量、异构、动态的大数据表达、组织、管理以及利用提供了一种更为有效的方式,使得网络的智能化水平更高,更加接近于人类的认知思维。
智能搜索,智能问答,社交网络,个性化推荐,情报分析,反欺诈等等
11. 总结
从技术来说,知识图谱的难点在于 NLP,因为我们需要机器能够理解海量的文字信息。但在工程上,我们面临更多的问题,来源于知识的获取,知识的融合。搜索领域能做的越来越好,是因为有成千上万(成百万上亿)的用户,用户在查询的过程中,实际也在优化搜索结果,这也是为什么百度的英文搜索不可能超过 Google,因为没有那么多英文用户。知识图谱也是同样的道理,如果将用户的行为应用在知识图谱的更新上,才能走的更远。
知识图谱肯定不是人工智能的最终答案,但知识图谱这种综合各项计算机技术的应用方向,一定是人工智能未来的形式之一。
12. 参考资料